
How to Integrate AI Tools for Your Business—Privately and Safely
 Read Time: 17 minutes
Read Time: 17 minutesWhat does private AI integration in business look like? How does it work with your data? Can it really be done safely, protecting your proprietary company data?
Note: Our live webinar on November 8, 2023, discussed the power of integrating AI into your company’s systems and explained how AI can be tailored to meet your specific needs while keeping all your proprietary information private. This article is the Part 2 recap of that webinar.
The evolution of Artificial Intelligence (AI) today is often compared to the revolutionary emergence of the internet. It's hard to fathom a modern business without an online presence in 2024. Similarly, AI adoption is expected to become equally ubiquitous. This transformative wave is upon us, swiftly reshaping industries.
Therefore, grasping the mechanics of AI tools is not just advantageous; it's imperative. This article will look at the fundamental concepts about how AI works with your data, what AI can do with the knowledge that's locked away in your company’s information, and how you can maintain the privacy of that information.
How Does AI Even Work?
Maybe you've used ChatGPT and wondered, “How on earth does this work? How does it understand my question?” The answer is not as mystical as it first appears. Let’s do a little fill-in-the-blanks exercise:
- One, two, three, ____.
- The sky is ____.
- It’s raining cats and ____.
More than likely, your brain filled in the blanks with the words four, blue, and dogs, respectively. This is because your brain readily recognizes patterns and can make predictions based on those patterns.
AI is powered by Large Language Models (LLMs) that work in a similar way. LLMs are fed enormous amounts of data. Because of being trained on millions of digitized books and websites, they have been trained to recognize patterns and make predictions. Because the amount of data is vast (and because they are machines), they can make predictions on things that humans don't even recognize as a pattern or sequence.
For example, if you type a question like “Why is the sky blue?” into ChatGPT, its underlying LLM will look at this as a prompt for “What is the most probable word to come next in this sequence?” It can recognize that the question is about the color of the sky. It has seen this subject before in its training data. Maybe it has seen this exact question many times before. It can therefore predict what the next word will be. So probably it's “the,” and then “sky,” and then “is,” and so on.
In the end, what seems like an intelligent answer to our question is really a series of predictions about what word comes next. This goes on until the so-called Stop Token is sent to trigger the end of the answer.
This is an extremely simplified explanation of a very complicated process, but we need to understand the foundation of how AI works so we can understand how to use it responsibly with sensitive company data.
How Custom AI Tools Can Work for Your Business
If you’ve been in business for any amount of time, you probably have a large amount of proprietary information in and about your company. This is proprietary data that commercial LLMs do not have access to and have not been trained on.
Therefore, an AI tool like ChatGPT is unable to answer specific questions about your business. For example, let's say we ask ChatGPT a very specific question about Jamie Smyth, the CEO of The Smyth Group:

Chat GPT doesn't have specific information about The Smyth Group or its CEO.
This would also be true for questions about your company, especially about something specific, such as policy, data, or training material.
However, if you were to give the LLM more context around your question, you would get a more useful answer. Using our example above, let’s copy the “About Us” page on thesmythgroup.com and paste it into ChatGPT, adding, “Given the following context, tell me what the first commercial program designed by The Smyth Group’s CEO was.”

Now it can answer the question correctly because it has the context to do so.
Context is key. Giving context to the large language model enables the AI to answer questions about information that it was not trained on.
The Role Your Information Plays With AI
The context of your company can likely be found in vast amounts of documents, databases, spreadsheets, policies, handbooks, wikis, and training manuals—and knowledge is undoubtedly locked away in these artifacts. You may have invested significant resources in creating training materials or information repositories. Is it possible that hardly anybody ever reads them? Is it just too tedious to find the information?
All that information is valuable context to an AI. Once it has access to your information, it can be used to quickly answer specific questions as often as needed.
What Happens to Your Documents
In order to enable an LLM to answer questions about your documents, you need to follow a three-step process. You can compare this process to stocking a library with your company documents, and then letting a robot quickly pull out the most relevant pages that contain information about the user's question.
So step one is stocking the library. The text in your documents is converted into so-called embedding vectors. These are numerical representations of each word that preserve their meaning. So the word "runs" in the sentence "The engine runs smoothly" will be represented by a different vector than the same word in the sentence "He runs a marathon." Saving those vectors in a vector database makes it possible to quickly find relevant context for a given question.

That brings us to step two. When a user asks a question about your proprietary information, relevant context is retrieved from the vector database. It's a bit like if you asked a question about outer space, and the robot pulled books about planets, stars, and astronauts to find the answer.
In the third and final step, the retrieved context along with the question is passed to the LLM to be answered. It's as if the robot reads through these retrieved documents quickly and combines the information it finds with what it already knows to come up with the best possible answer to your question. The robot is, in effect, learning from these documents on the spot and then explaining the answer to you in its own words.
Transforming your documents into an embedding model that is saved in the vector database is necessary, but it is possible to make it a secure and private process. Since most businesses will choose a partner to do the embedding, it’s crucial to answer the following questions: How does that partner treat and respect your data? How and where is the processing happening? How are your original documents handled? Where do the vector databases live? Who has access to them? How are they secured? Where do the user prompts and responses go?
So imagine that now you have your context, and you were diligent about securing it during the embedding process. Does that mean you’re home free? Not quite. Let’s talk about RAG—Retrieval Augmented Generation.
What Is Retrieval Augmented Generation?
Let’s ignore the “retrieval augmented” part for a moment and just focus on “generation.” “Generation” in generative AI means that you input a query, and the AI generates an output for you.
In our previous example, we asked ChatGPT a question about The Smyth Group, and it generated a response explaining that it didn’t know the answer. Our question was put into an application (ChatGPT) and that query was sent along to the large language model behind ChatGPT (GPT-4) unchanged. The LLM didn’t know the answer, and that generated output was passed on to us.
Integrating retrieval augmentation into the process enables a conversational interaction with your documents, significantly enhancing the capabilities of AI as a tool. We’ll use our same example from before, but this time we will have our vector database available to the AI. When we ask the application our question (“What was the first commercial program designed by The Smyth Group’s CEO?”), instead of sending the question unchanged to the LLM, it will now do a similarity search in the vector database. It retrieves relevant context and will now send an augmented query to the LLM. This augmented query will consist of something like, “Given the following context…please answer the question, ‘What was the first commercial program designed by The Smyth Group’s CEO?’”
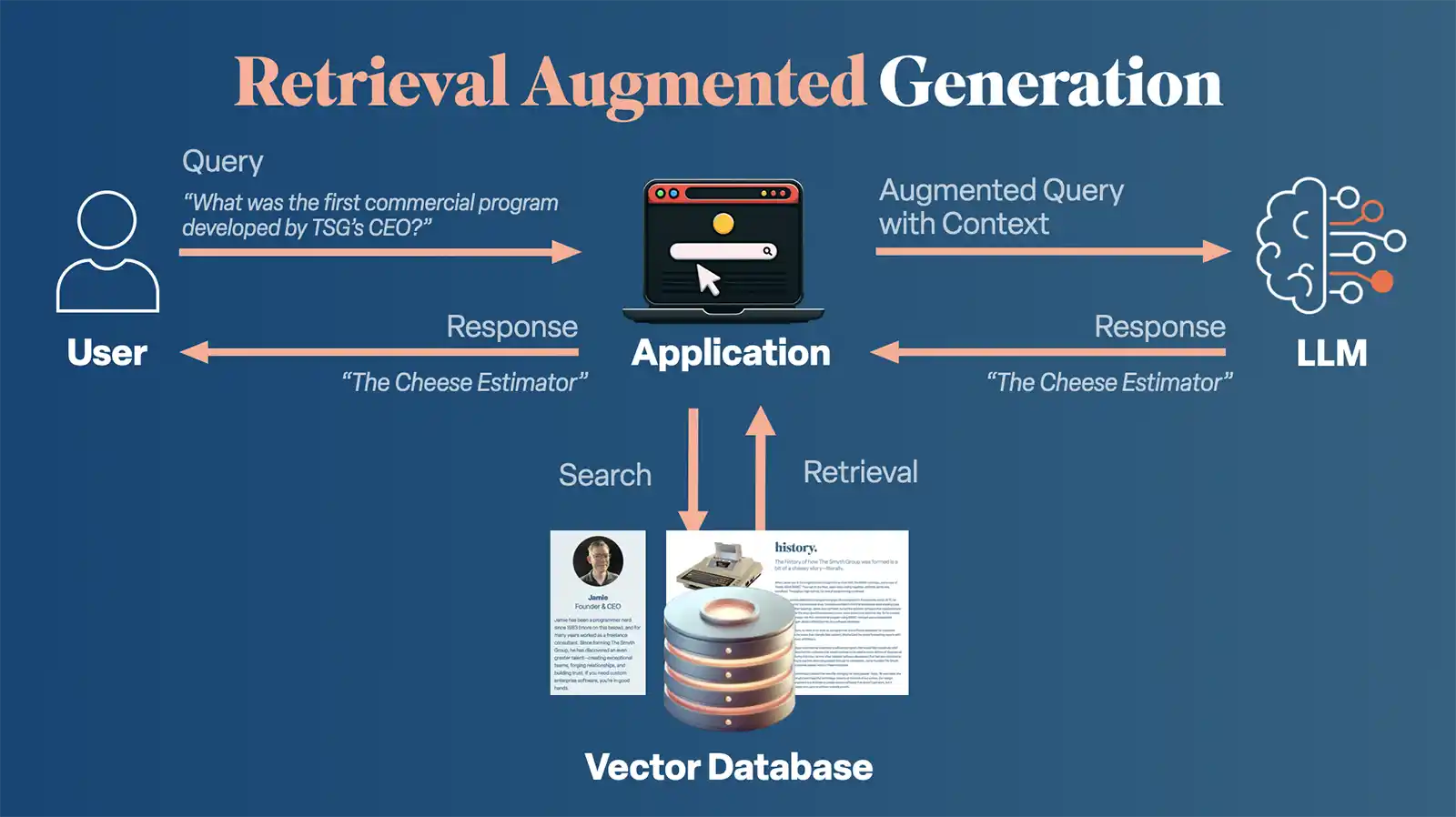
Sound familiar? It’s what we manually entered earlier in order to get a correct answer from ChatGPT. But this time, the relevant context was found automatically, passed along to the LLM with our question, and the correct answer was generated.
Other search technologies can be added as well. A product database, with all the products your company sells, could be tapped into. Or an API call could query a third-party service, perhaps for pricing information on flights or other related information.
One very powerful use case would be to hook into your company’s single sign-on and role-based authentication. This means the application could take into account who is asking the questions and whether they are authorized to see the answers. A manager, for example, could log in with their credentials and ask a question about employee salaries. The search and retrieval process would know that the manager has the right to see that data and would return it to them. On the other hand, someone logged in as a regular employee could ask the same question but would not get the same results.
Maintaining Privacy During Ingestion
For a system this powerful to work, the initial ingestion stage needs to be done thoroughly and responsibly. The partner you choose to develop your system needs to respect your data and invest time in knowing its shape. Often, data needs to be cleaned up to remove noise or restructured so that context can be found more effectively. When this is done well, it can lead to very powerful systems.
Entrusting a third-party service with the complete processing of your documents is a viable path, provided you're comfortable with them seeing every part of every document. However, a more private alternative exists: conducting the data ingestion process within your own company's network or services. This ensures your sensitive information remains strictly within your control.
However, the vector database copies of your data will still need to live somewhere, so careful planning around your infrastructure's setup and stringent access controls are essential to safeguard your data's integrity and confidentiality.
Maintaining Privacy During Inference
In the second stage, your data engages in a process we term “inference.” Here, a query, enriched with contextual nuances, is processed by an LLM. It's crucial to maintain stringent security throughout this stage, akin to all other phases. The real vulnerability, however, emerges not in the LLM itself but in how the web application that interfaces with the LLM is constructed. If this application is developed without a strong focus on security, it becomes a potential weak point. Regardless of the strength of other security measures in place, a poorly secured web application can expose sensitive information derived from your query and context. This situation aptly illustrates the adage: “A chain is only as strong as its weakest link”' Hence, the meticulous efforts invested during the data ingestion phase could be nullified by a web application that hasn't been developed with equal diligence and attention to security.
Today, most big data breaches are due to insecure web applications, so asking the right questions and being informed about every step your data takes through this chain is the best way to keep your information secure.
This doesn’t mean that you can’t have third parties involved. There are many respectable cloud-based solutions available, such as OpenAI, Microsoft Azure, and AWS, to name a few. All of them have AI offerings, and it is up to you to decide if you are comfortable with their security and privacy settings.
On the other hand, there are also open source large language models such as Llama 2 from Meta, Falcon 180b, MPT-7B and others. It’s possible to run these on your own hardware or virtual hardware within your company’s system. The downside to this is a decrease in performance due to hardware limitations.
Ultimately, it comes down to balancing trust, performance, and cost. Security in a complex system doesn’t have a simple answer, but rest assured it is possible to leverage AI in a private way by balancing these different factors.
SaaS and Out of the Box Solutions
Everyday more AI companies spring up like mushrooms, and a lot of them offer out-of-the-box solutions. Chatting with your documents via a quick plug-in may seem very attractive. These companies promise security and privacy, but you must proceed with caution. Understanding the journey your data undertakes just to be understandable to an AI allows you to grasp the potential risks involved, and you can no doubt imagine how easy it would be for these companies to funnel your private information through a number of third parties that you know nothing about.
Your data is an invaluable asset and deserves a partner who treats it with the utmost respect—a partner who doesn't just shovel your data into some funnel or furnace like coals, but respectfully analyzes what data you have in your company and then builds a solution that's a perfect fit for you.

What is needed to build a custom AI tool?
You will need a number of tools if you decide to build your own custom software system using AI. Obviously, the brains of the operation will be your LLM. The popular ones are OpenAI’s GPT, Anthropic’s Claude, Amazon’s Titan, or an open source model like Meta’s Llama 2.
For your vector databases, you’ll likely need a hosted cloud solution like Pinecone. If you’re working off your own hardware, there are open source solutions such as Chroma, Faiss, or Elasticsearch.
You’ll also need tools for data retrieval and prompt building. Two of the most popular ones are LangChain and LlamaIndex. These will help you build chains of steps for what gets sent to the LLM, how its answers are interpreted, and maybe some additional steps before an answer is returned to a user.
For our webinar, we built a live demo that ran 100% locally on a laptop. We used the HTML of every page of our TSG website as our context. For our vector database we used open source ChromaDB, Llama 2 as our LLM, and LangChain to tie it all together.
Back to the Future with AI
If you had known in 1994 how quickly the internet would grow and how impactful it would be on our daily lives, would you have done anything differently? Had you grasped its forthcoming influence, you might have approached its integration into your business with even greater foresight.
Today, we stand on the cusp of another transformative era with AI technology. Harnessing this power for your business is not just advantageous—it's visionary. Nevertheless, the foundation of this venture must be trust: trust in either the engineers that you engage for a custom solution, or trust in the off-the-shelf SaaS tool you select. Either way, don't compromise when it comes to where you place your trust when integrating private AI tools with your business.



We are custom software experts that solve.
From growth-stage startups to large corporations, our talented team of experts create lasting results for even the toughest business problems by identifying root issues and strategizing practical solutions. We don’t just build—we build the optimal solution.
From growth-stage startups to large corporations, our talented team of experts create lasting results for even the toughest business problems by identifying root issues and strategizing practical solutions. We don’t just build—we build the optimal solution.